[파이썬 코딩의 기술] Concurrency and Parallelism(병행성과 병렬성) - subprocess, multithread
by Dojin Kim
Effective Python - Brett Slatkin을 읽으면서 공부 및 정리를 하며 글을 쓰고 있습니다.
Concurrency와 parallelism의 차이가 무엇인지 살펴보려고 한다. 해당 내용은 stackoverflow-what-is-difference-between-concurrency-and-parallelism 에서 가지고 왔다.
Concurrency는 2개 혹은 그 이상의 작업들이 시작, 실행, 끝나기까지 서로 겹치는 시간대에 이뤄질 수 있음을 의미한다. 꼭, 여러 작업이 동시에 시작하는 것을 의미한다. 예를 들어, 하나의 CPU core를 가진 컴퓨터에서 os는 싱글 프로세서에서 실행되는 프로그램들을 왔다 갔다 한다. 그래서 마치 모든 작업들이 동시에 이뤄지는 것처럽 보이는 것이다.
Parallelism은 말 그래도 작업들이 동시에 진행되는 것이다. 예를 들어, multiple CPU core를 가진 컴퓨터에서 multiple 프로그램들이 동시에 실행이 된다. 각 CPU core는 다른 프로그램들이 동시에 진행될 수 있도록 해준다.
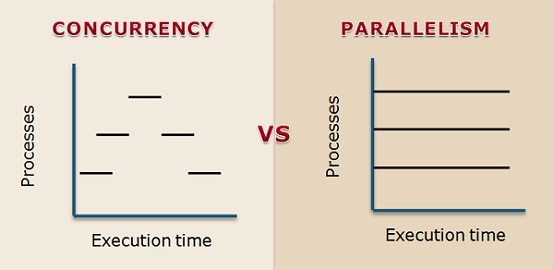
둘의 가장 큰 차이점은 속도이다. 프로그램이 parallel하게 진행이 되면 전체 실행시간에서 반을 줄 일 수 있다. 반면에, concurrent 프로그램은 여러 프로그램들이 돌아가는 것처럼 보이지만 전체 실행 시간은 줄어들지 않는다.
Python에서 concurrent 프로그램 매우 쉽게 작성할 수 있다. Parallel 프로그램도 system calls, subprocesses, C-extenssions를 사용해서 작성할 수 있지만, 실제로는 concurrent Python 코드를 parallel하게 만드는 것은 매우 어렵다. 그럼에도, 각 상황마다 Python을 최대한 활용하기 위한 방법들을 알아볼 예정이다.
Item 36: Child Processes 관리하기 위해 subprocess 사용하기
Python에 의해 시작된 child process들은 parallel로 실행될 수 있다. 그래서 python으로 하여금 모든 CPU의 core를 사용해서 프로그램의 throughpu을 최대화할 수 있게 해준다.
지금까지 Python으로 subprocess 실행시키는 방법으로는 *popen, open2, os.exec** 등이 있었다. 하지만, 최근 Python에서 child process를 관리하는 최적의 방법은 subprocess라는 built-in 모듈을 사용하는 것이다. 이 subprocess를 사용하는 것은 매우 간단하다.
proc = subprocess.Popen(
[‘echo’, ‘Hello from the child!’],
stdout=subprocess.PIPE)
out, err = proc.communicate()
print(out.decode(‘utf-8’))
# Hello from the child!
Popen constructor가 process를 시작한다. communicate method는 child process의 결과를 읽고 종료까지 기다린다. Child process는 parent process 인 Python 인터프리터로부터 독립적으로 실행된다.
# child method만들어서 run
def run_sleep(period):
proc = subprocess.Popen([‘sleep’, str(period)])
return procstart = time()
procs = []
for _ in range(10):
proc = run_sleep(0.1)
procs.append(proc)
# communicate method
for proc in procs:
proc.communicate()
end = time()
print(‘Finished in %.3f seconds’ % (end - start))
subprocess를 사용하면 parallel(병렬)하게 프로그램을 사용할 수 있다. Openssl command-line tool을 사용해서 어떠한 데이터를 encrypt(암호화)한다고 가정해보자. Child process를 cmd-line arguments로 시작하고 I/O를 pip하는 것은 쉬운 일이다.
def run_openssl(data):
env = os.environ.copy()
env[‘password’] = b’\xe24U\n\xd0Ql3S\x11’
proc = subprocess.Popen(
[‘openssl’, ‘enc’, ‘-des3’, ‘-pass’, ‘env:password’],
env=env,
stdin=subprocess.PIPE,
stdout=subprocess.PIPE)
proc.stdin.write(data)
proc.stdin.flush() # Ensure the child gets input
return proc
여기서 랜덤한 byte들을 암호화하는 함수에 pipe를 한다. (실제 상황에서라면 유저의 input, network socket등이 될 것이다)
child process가 parallel하게 run 하고 input을 받게 된다. communicate method로 모두가 끝날 때 까지 기다리고 최종 결과를 받는다
procs = []
for _ in range(3):
data = os.urandom(10)
proc = run_openssl(data)
procs.append(proc)
for proc in procs:
out, err = proc.communicate()
print(out[-10:])
# b’o4,G\x91\x95\xfe\xa0\xaa\xb7’
# b’\x0b\x01\\xb1\xb7\xfb\xb2C\xe1b’
# b’ds\xc5\xf4;j\x1f\xd0c-‘
만약 child process가 끝나지 않는 것이 걱정되거나 input 혹은 output pipe가 어쩌다가 막히는 것이 걱정되면 communicate method에 timeout 인자를 전달하는 것도 방법이다. 인자로 전달된 시간 안에 child process가 반응을 안하면 exception을 발생시키고 종료를 한다.
proc = run_sleep(10)
try:
proc.communicate(timeout=0.1)
except subprocess.TimeoutExpired:
proc.terminate()
proc.wait()
print(‘Exit status’, proc.poll())
이 timeout인자는 Python 3.3 혹은 그 이후 버전에서만 사용이 가능하다.
Item 37: Thread를 Blocking I/O용으로 사용하고, Parallelism용으로는 사용하지 않기
Python의 표준 구현 방법은 CPython이라고 불린다. CPython은 Python 프로그램 두 단계로 실행한다. 먼저, source text를 bytecode로 파싱하고 컴파일한다. 그 다음에는 bytecode를 stack을 기반으로 한 인터프리터에서 실행한다. Python은 coherence(일관성, 결합성)를 강제하는데 이 메커니즘은 global interpreter lock(GIL)이라고 불린다.
본래, GIL은 상호배타적이어서 Cpython이 preemptive(선점적) multithreading, 한 thread가 다른 thread를 interrupt해서 프로그램의 통제하는 것,의 영향 받는 것을 방지한다.
하지만, GIL도 치명적인 단점이 있다. Java나 C++로 작성한 프로그램에서 multi thread가 있으면 multiple CPU core를 동시에 사용할 수 있음을 의미한다. Python이 multi thread를 지원하긴 하지만, GIL은 한 타임마다 한 thread씩만 실행시킨다. 즉, GIL을 사용하면 parallel computation이 되지 않는다는 것이다.
예를 한번 보자, 밑에는 factorization하는 알고리즘인데 큰 숫자들을 순차적으로 함수에 넣었을 때 compute하는데 꽤 긴 시간이 걸린다.
# factorization 하는 알고리즘
def factorize(number):
for i in range(1, number + 1):
if number % i == 0:
yield i
numbers = [2139079, 1214759, 1516637, 1852285]
start = time()
for number in numbers:
list(factorize(number))
end = time()
print(‘Took %.3f seconds’ % (end - start))
# Took 1.040 seconds
다른 언어에서라면 multi-thread를 사용해서 CPU core을 효율적으로 사용하는 것이 가능하다. 여기서 이제 Python으로 thread를 사용해서 결과를 보려고 한다. list의 개수 만큼 thread를 형성하고 thread가 실행이 되게 한다. 그러고 나서 모든 thread가 실행을 마칠 때 까지 기다렸다가 시간을 비교해봤다.
from threading import Thread
class FactorizeThread(Thread):
def __init__(self, number):
super().__init__()
self.number = number
def run(self):
self.factors = list(factorize(self.number))
start = time()
threads = []
for number in numbers:
thread = FactorizeThread(number)
thread.start()
threads.append(thread)
for thread in threads:
thread.join()
end = time()
print(‘Took %.3f seconds’ % (end - start))
# Took 1.061 seconds
해당 프로그램이 걸린 시간을 보면 thread를 사용하지 않았을 때보다도 더 오래 걸린 것을 볼 수 있다. 다른 언어에서라면 multi-thread를 사용해서 최대 4배(list 개수) 빨라졌을 것이다. 이 예제로 GIL이 multiple CPU를 최대로 활용하지 못한다는 것을 볼 수 있다.
CPython으로 multiple core를 사용하는 방법이 있긴 하지만, 표준 Thread class로는 불가능하다.
그렇다면 다음과 같은 질문이 생길 수 있다 - Python은 왜 thread를 지원할까? 이에 대한 이유는 다음과 같다:
- multiple thread로 여러 task를 동시에 실행 시킬 수 있다. 여러 task들의 순서를 정하는 등 직접 구현하는 것은 어렵다. Thread를 사용하면 여러 task들을 Python이 알아서 실행시킨다. (물론, GIL 때문에 parallel하게 이뤄지지는 않는다)
- Python이 thread를 지원한는 것은 blocking I/O를 다루기 위함이다. Blocking I/O는 특정한 system call에서 발생하고 파일 읽기, 쓰기, 네트워크와 상호작용 등을 포함한다.
Blocking I/O에 thread 사용하기
예를 들어, serial port로 원격 조종되는 헬리곱터에 signal을 보낸다고 가정해보자. 예시에서 select라는 system call을 사용할 것인데, 이는 os에게 0.1초 block을 요청한 다음 프로그램으로 돌아간다.
import select
def slow_systemcall():
select.select([], [], [], 0.1)
start = time()
for _ in range(5):
slow_systemcall()
end = time()
print(‘Took %.3f seconds’ % (end - start))
# Took 0.503 seconds
이 프로그램은 아직 thread를 사용하지 않았고, 가장 큰 단점은 signal을 보내면서 움직임을 가져갈 수 없다는 것이다. Main thread가 select system call에 block되었기 때문이다. Blocking I/O와 computation이 동시에 일어나야 제대로 작동을 할 수 있다. 이럴 때 system call을 thread로 변경해야 한다.
start = time()
threads = []
for _ in range(5):
thread = Thread(target=slow_systemcall)
thread.start()
threads.append(thread)
def compute_helicopter_location(index):
# …
for i in range(5):
compute_helicopter_location(i)
for thread in threads:
thread.join()
end = time()
print(‘Took %.3f seconds’ % (end - start))
# Took 0.102 seconds
System call만 thread로 적용하니 이전에 비해 5배나 빨라진 것을 볼 수 있다. Python thread가 GIL로 인해 parallel computaion이 불가능하지만 system call은 parallel로 이뤄질 수 있음을 확인할 수 있다.
결론적으로, Python의 thread를 parallel하게 사용하고 싶으면 I/O blocking하는 상황에서 사용해야 한다. 그 외에는 thread로 CPU core의 자원을 최대로 활용하기 어렵다.
Subscribe via RSS
{kind=link}