[핸즈온 머신러닝-3] Classification
by Dojin Kim
Hands On ML
핸즈온 머신러닝 영어 PDF를 읽고 공부하면서 내용을 정리하고 있다. 정리에 나온 대부분의 코드와 이미지들은 해당 PDF에서 가져왔다.
Chapter 3 - Classification
Supervised Learning(지도학습)에서 Regression(회귀)와 Classification(분류)가 가장 많이 사용된다. Regression은 주어진 입력에 대해 값을 예측하는 것이기에 연속적인 속성을 가지고 있고, classification은 주어진 입력이 어떤 클래스(혹은 라벨)에 속하는지 예측하는 것이기 때문에 이산적인 속성을 가지고 있다. [핸즈온 머신러닝 - 2장]에서는 regression을 사용해서 집값을 예측했고, 이 때 Linear Regression, Decision Tree, Random Forset와 같은 알고리즘들을 사용했다.
이번 [핸즈온 머신러닝 - 3장]에서는 classification에 대해 더 살펴보려고 한다. 모든 코드는 Jupyter notebook에서 작성되었다.
3.1 MNIST
Classification에 대해 공부할 때 가장 많이 사용되는 dataset은 MNIST dataset이다. 프로그래밍 언어를 처음배울 때 “Hello World”를 콘솔창에 띄우는 연습하는 것처럼, 머신러닝에서는 이 dataset을 다뤄서 예측하는 것을 연습한다.
MNIST dataset은 0~9까지 숫자를 손으로 작성된 data들의 모음이다. 해당 dataset은 Scikit-Learn로 쉽게 불러와서 사용할 수 있다.
from sklearn.datasets import fetch_openml
# mnist 784 dataset을 불러오는 코드
mnist = fetch_openml('mnist_784',version=1)
mnist_784 dataset은 70,000개의 이미지들의 모음이고 각 이미지들은 784개의 feature(특징)들을 가지고 있다. Feature들의 개수가 784인 이유는 각 이미지들이 28 x 28 픽셀 형식이기 때문이다 (28 x 28 = 784). 그리고 각 pixel은 0~255의 값을 가지고 있다. 0에 가까울 수록 흰색이고 255에 가까울 수록 검정색이다.
X, y = mnist['data'], mnist['target']
X.shape
# (70000, 784)
y.shape
# (70000,)
Dataset에 있는 이미지 하나를 예시로 보고 싶으면 feature 벡터를 28x28로 다시 변환을 해서 imshow() 함수를 사용하면 된다. Feature 벡터이기 때문에 1 x 784 형태이고, 28x28 사이즈의 이미지로 보기 위해서는 변환을 해야지만 볼 수 있는 것이다.
%matplotlib inline
import matplotlib as mpl
import matplotlib.pyplot as plt
# dataset의 가장 첫 data 받아옴
digit = X[0]
# 벡터 변환
digit_img = digit.reshape(28, 28)
plt.imshow(digit_img, cmap = mpl.cm.binary, interpolation="nearest")
plt.axis("off")
plt.show()
처음에 dataset의 가장 첫 index에 위치한 숫자를 불러왔고 28x28로 변환을 해줬다. 그 다음에 matplotlib라는 라이브러리로 해당 data를 시각화했다. 해당 코드를 돌려보면 숫자 5가 나오는 것을 볼 수 있다.
이제 학습을 시작하기 전에 dataset을 training set과 test set으로 나눠야 한다. 나누는 법은 Python의 slicing사용하면 간단하게 할 수 있다. 이미 dataset이 랜덤하게 셔플되어있기 때문에 따로 작업을 해줄 필요가 없다. Training set으로는 60,000개, test set으로는 10,000개를 지정해줬다.
X_train, X_test, y_train, t_test = X[:60000], X[60000:], y[:60000], y[60000:]
3.2 Binary Classifier 학습하기
전체 MNIST를 분류하기 전에 문제를 단순화해서 하나의 숫자(5와 5가 아닌 숫자들)로만 구분하려고 한다,
y_train_5 = (y_train==5)
y_test_5 = (y_test==5)
이제 classifier를 선택하고 학습을 시켜야 한다. Stochastic Gradient Descent (SGD) classifier를 사용할 것인데, 이 classifier는 큰 dataset을 효율적으로 잘 다루기 때문이다. SGD는 training instance들을 독립적으로 다룬다 (그래서 online learning에도 적합하다). **
SGD의 파라미터 중에 random_state가 있고 값으로는 보통 42가 **전달된다. 정확히 왜 42가 전달되는지는 모르겠지만, 해당 함수를 다루는 많은 도큐먼트들에서 42를 전달하는 경우가 많다. 값에 초점을 두기보다는 random_state 자체가 무슨일을 하는지 알아야 한다. random_state는 랜덤 숫자 생성기를 초기화하는데 사용된다. 고정된 숫자를 인자로 전달하게 되면 항상 같은 순서의 결과가 리턴되는 것이 보장된다, 그래서 결과값을 확인할 때 정확하게 할 수 있는 것이다. (참고자료: random_state)
from sklearn.linear_model import SGDClassifier
sgd_clf = SGDClassifier(random_state=42)
sgd_clf.fit(X_train, y_train_5)
sgd_clf.predict([digit])
# array([True])
3.3 Performance 측정
Classifier의 퍼포먼스를 측정하는 방법에는 여러 방법들이 있다.
3.3.1. Cross-Validation
Model을 평가하기 좋은 방법중 하나는 cross-validation을 사용하는 것이다.
잠시 짧게 cross-validation이 무엇인지 살펴보려고 한다. [3months님의 블로그], [nonmeyet님의 블로그]에서 해당 개념을 이해하는 것에 도움을 받았다. Cross-validation은 주로 dataset의 크기가 작을 때 성능 평가가 잘 이뤄지지 않을 때 사용하는 검증방법이다. 데이터가 많이 없다면 validation set을 얼마나 또 어떠한 데이터를 잡느냐에 따라서 성능이 변할 수 있다고 한다. Cross-validation을 사용하면 모든 데이터들이 최소 한 번씩 validation set으로 사용될 수 있게 된다.
이 때 Dataset을 k개로 나눠서 cross-validation을 하게 되는 것을 K-fold Cross Validation이라고 부르게 되는 것이다. 예를 들어, k가 3이고 training dataset의 크기가 300이라면 A-0~99, B-100~199, C-200~299로 나누는 것이다. 그러고 총 3번을 학습하는 것이다.
- 처음에는 A를 validation set으로 두고 B+C학습
- 다음에는 B를 validation set으로 두고 A+C학습
- 마지막으로 C를 validation set으로 두고 A+B학습
- 각 fold의 에러를 바탕으로 최적을 모델을 찾는다
이제 K-fold Cross Validation의 개념을 어느정도 이해한 것 같으니 코드 작성으로 넘어가려고 한다. Scikit-Learn에서 cross_val_score()라는 함수를 제공하고, 해당 함수로 SGDClassifier에 K-fold cross validation을 적용해서 성능 평가를 할 수 있게 된다. 파라미터 중에 cv가 있는데, 인자로 전달되는 숫자가 fold의 수 - 즉, k가 되는 것이다.
from sklearn.model_selection import cross_val_score
cross_val_score(sgd_clf, X_train, y_train_5, cv=3, scoring="accuracy")
# array([0.963xx, 0.937xxx, 0.956xxx])
학습했던 모델이 93% 정도의 정확도를 가지게 된다. 꽤 높은 수치이지만, dataset의 왜곡 때문에 정확도가 높게 나왔다고 볼 수 있다. 70,000장 중에 5가 10%밖에 없고 5가 아닌 데이터는 90%이다. 그렇기 때문에 어떤 data가 들어와도 5가 아니라고 예측해버려도 90%의 정확도를 가지게 될 수 있는 것이다. 이러한 이유때문에 정확도가 높게 나왔지만, 예측을 잘하는 모델이라고 보기 힘든 것이다.
3.3.2 Confusion Matrix
이러한 경우에 성능을 제대로 평가하기 위해서 confusion matrix를 사용하는 것이 낫다. 해당 방법의 기본 적인 아이디어는 class A instance가 class B로 classify된 경우를 세는 것이다. 예를 들어, 5를 3으로 오인한 경우, 3을 5로 오인한 경우들을 살펴보는 것이다.
일단 confusion matrix를 계산하려면 먼저 예측된 결과가 필요하다(그래야지 언제 오인을 했는지 알 수 있다).
from sklearn.model_selection import cross_val_predict
y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3)
cross_val_predict() 함수도 위에서 진행한 cross_val_score()와 같게 K-fold cross validation을 사용한다. 다만, 점수들을 리턴되지 않고 각 test fold에 대한 예측값들이 리턴된다. 이 때 clean한 예측값들을 얻을 수 있다고 표현된다, clean이라 함은 training 이전에 다른 데이터를 참고하지 않은 모델을 의미한다.
예측값들을 얻게 되면 그 값들을 confusion_matrix에 타겟 class (y_train_5) 와 예측된 class (y_train_pred)를 전달한다.
from sklearn.metrics import confusion_matrix
confusion_matrix(y_train_5, y_train_pred)
# array([[53057, 1522],
# [1325, 4096]])
각 row(열)는 실제 class를 의미하고, column(행)은 예측된 class를 의미한다.
- 첫째 row의 53,057은 non-5 이미지들이고 바르게 분류 됐음을 의미한다 - true negative
- 1522는 다른 숫자들이 5로 잘못 분류된 수를 의미한다 - false positive
- 둘째 row의 1325는 5가 다른 숫자들로 잘못 분류된 수이다 - false negative
- 4096은 5가 5로 잘 인식된 경우의 수이다 - true positive
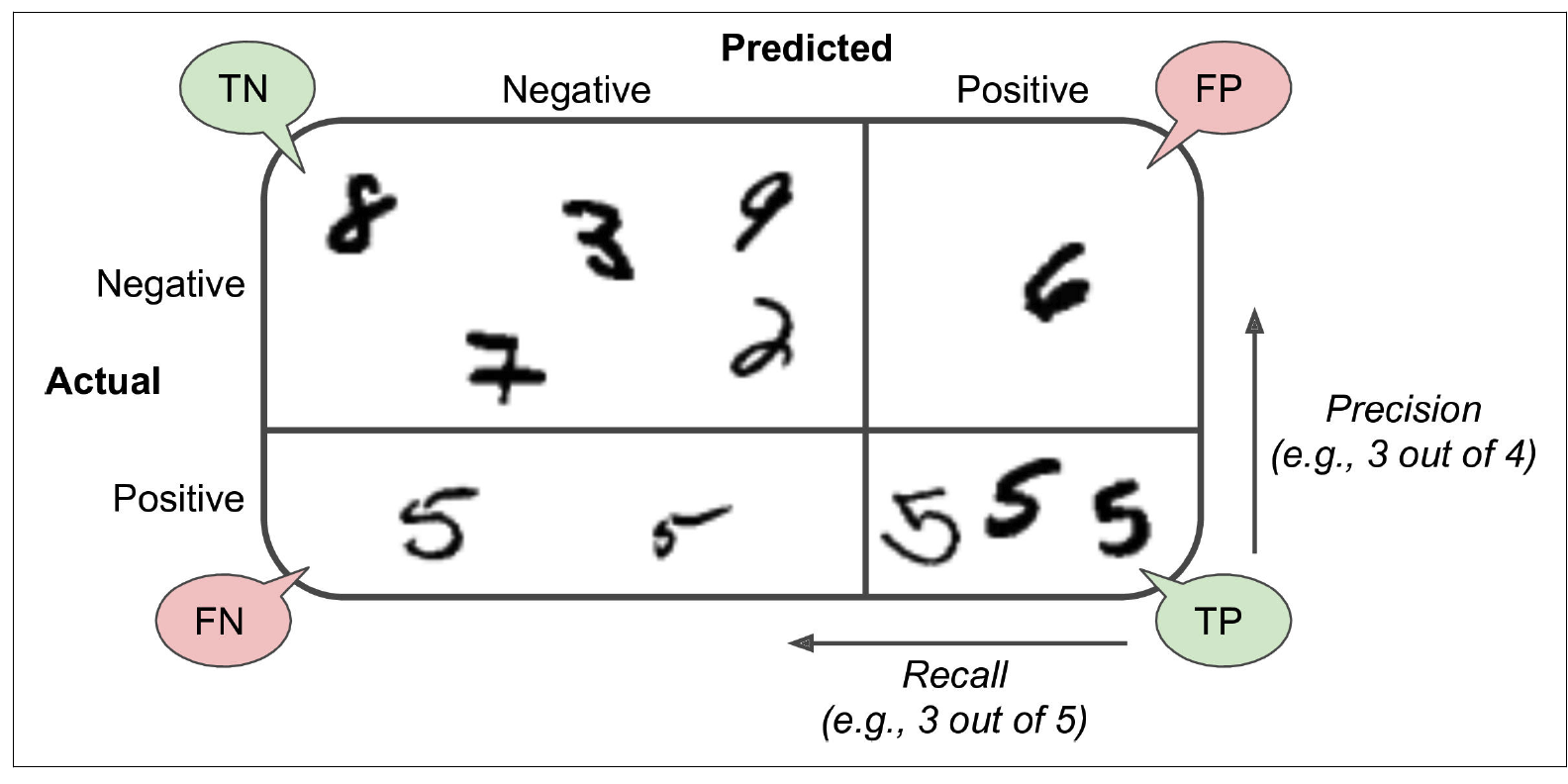
Positive 예측값들(5를 5로 인식, 다른 숫자들을 5로 인식)을 precision이라고 부른다.
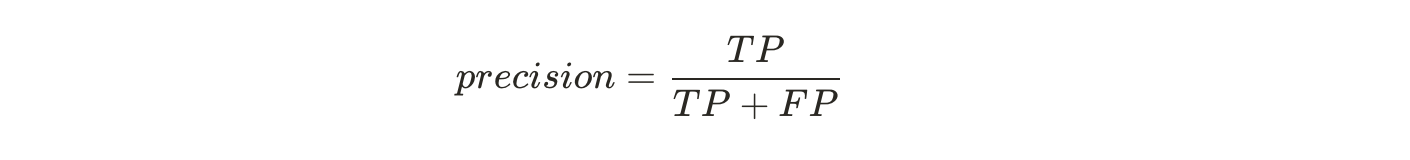
Precision의 정확도가 100%(혹은 1/1)가 되기 위해서는 FP가 0이어야 한다. 즉, 다른 숫자들을 5로 오인하는 경우가 전혀 없어야 한다. Precision가 좋은 것만으로 classifier의 성능이 완벽하다고는 할 수 없다, 왜냐하면 precision은 5가 다를 숫자로 인식된 경우를 생각하지 못하기 때문이다.
그래서 precision으 주로 recall(True Positive Rate)이랑 같이 사용된다. Recall은 classifier에 의해 예측하고 싶은 class가 제대로 예측된 비율을 의미한다(5가 5로 인식된 비율)
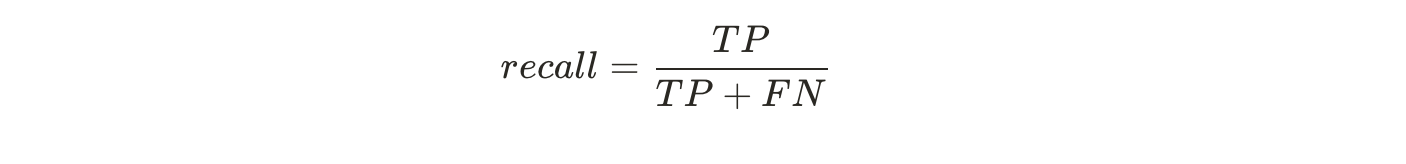
Precision and Recall
Scikit-Learn으로 precision과 recall을 바로 계산할 수 있다. 위에서 나온 식들을 이용해서 값을 계산해준다. TP = 4096, FP = 1522이기 때문에 Precision은 0.729정도가 나오게 된다. FN = 1325이기 때문에 Recall은 0.755정도가 나오게 된다.
from sklearn.metrics import precision_score, recall_score
precision_score(y_train_5, y_train_pred)
# 4096 / (4096 + 1522) = 0.729xxxx
recall_score(y_train_5, y_train_pred)
# 4096 / (4096 + 1325) = 0.755xxxx
Classifier가 어떤 숫자를 5로 예측했을 때 해당 숫자가 진짜 5일 확률(precision)이 72.9%인 것이다. 그리고 전체 5 데이터 중에서 75.6%의 5들만 detect(recall)할 수 있다는 것이다.
일반적으로 precision과 recall을 따로 구하기 보다 더 간편하게 하나의 metric인 F1 score로 통합을 한다. F1 score는 precision과 recall의 harmonic mean(조화평균)이다. 조화평균이란 n개의 양수가 있을 때 그 양수들을 역수로 만들고, 그 다음에 그 역수들을 산술평균한 것의 역수를 의미한다. (F-sore와 harmonic mean, 조대협님의 블로그 참고)
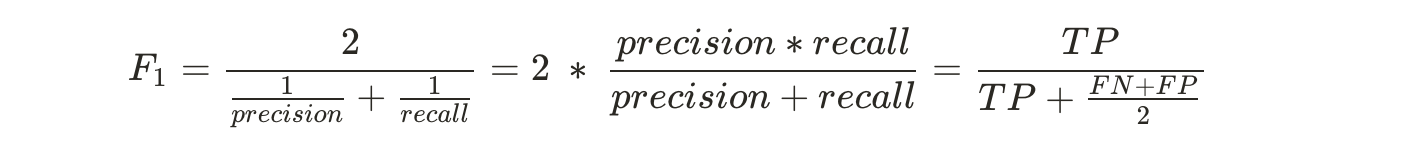
이 식에서 precision과 recall이 양수이다. 그렇기 때문에 해당 값들을 먼저 역수로 변환을 한다. 그 다음에 역수들의 산술평균을 구해야 하고 precision & recall이 2개이기 때문에 2로 나눈다. 그 다음에 그 값을 다시 역수로 만들어준다.
Harmonic mean은 낮은 값에 더 많은 weight를 부여한다. 그래서 ecall과 precision이 높을 때만 F1 score도 높게 나온다.
from sklearn.metrics import f1_score
f1_score(y_train_5, y_train_pred)
# 0.742xxxx
F1 score는 유사한 precision과 recall을 선호한다. 하지만 상황에 따라서 precision이 높아야 하는 경우가 있고, recall이 높은게 나은 경우가 있다. 예를 들어, 아이들에게 안전한 컨텐츠를 분류하려고 할 때 classifier가 몇몇 좋은 컨텐츠들을 놓치는 대신에 (낮은 recall) 안 좋은 컨텐츠를 최대한 막는 것(높은 precision)이 더 낫다. 반면에, CCTV로 범죄자를 감시 할 때 precision이 낮더라도 recall이 높은 것이 더 낫다. 즉, 범죄자가 아닌 시민들을 범죄자로 인식해서 경비원이 여러번 확인하는 경우가 생기더라도 최대한 모든 범죄자들이 감시 가능해야 한다.
Precision과 recall이 둘 다 높으면 최고겠지만, 항상 둘은 tradeoff 관계에 있다. 하나가 높으면 필연적으로 다른 하나는 줄어든다.
Precision/Recall TradeOff
Tradeoff를 이해하려면, SGDClassifier가 분류를 할 때 어떤 과정을 거치는지 알아야 한다. SGD는 각 instance마다 decision function(class결정하는 함수)에 기반해서 점수를 계산하고 점수가 threshold(특정 값)보다 높으면 instance를 positive class, 낮으면 negative class로 분류한다.
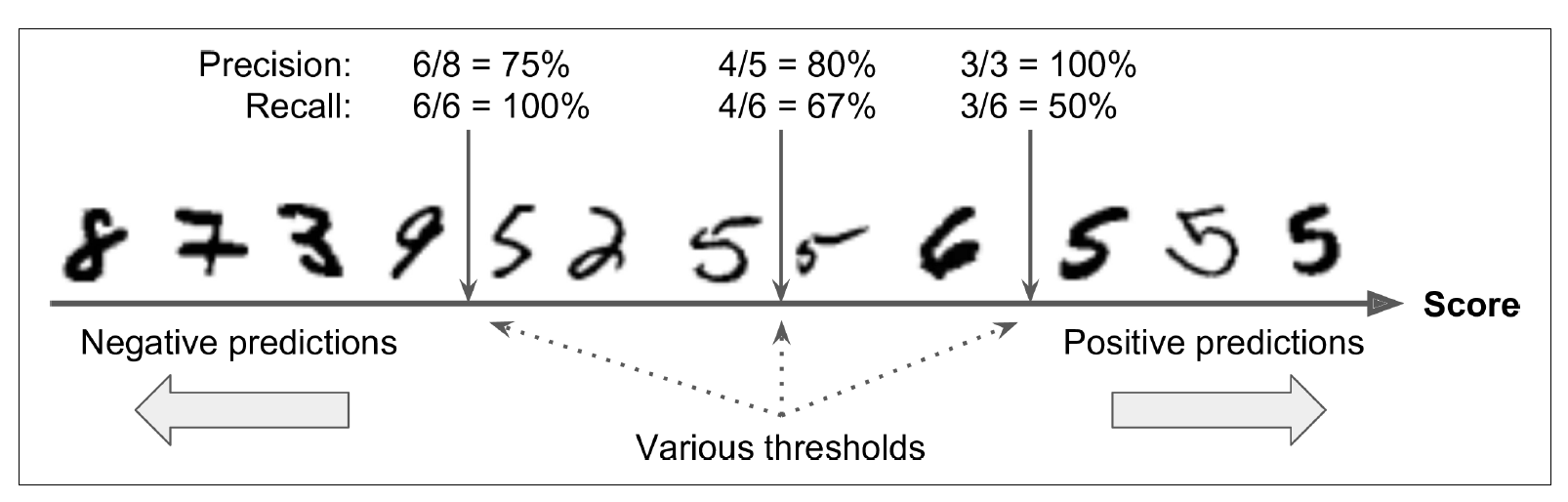
decision threshold가 중간 라인이라고 가정을 했을 때, 오른쪽에 ‘5’-4개, ‘6’-1개가 있다. 그래서 precision이 80%(4/5=0.8)이다. 하지만 전체 5가 6개인데 그 중에서 4개만 올바르게 예측했기 때문에 recall은 67%(4/6=0.67)이다.
만약 threshold를 올려서 오른쪽으로 라인을 옮기게 되면 precision은 100%가 되지만, recall은 50%로 하락한다. Threshold를 왼쪽으로 옮기면 precision은 75%로 하락하지만, recall은 100%가 된다.
Scikit-Learn에서는 유저가 threshold를 직접 제어하지 못하게 설정을 했다. 하지만, 각 instance들의 점수를 알려주는 decision_function()을 호출할 수 있다. 해당 method의 리턴값을 사용해서 threshold가 얼만지에 따라 classifier가 올바르게 예측할 수 있는지 확인할 수 있다.
y_scores = sgd_clf.decision_function([digit])
y_scores
# array([2412.5317])
thresold = 0
y_digit_pred = (y_scores > threshold)
# array([True])
threshold = 8000
y_digit_pred = (y_scores > threshold)
# array([False])
숫자 5에 대한 classifier의 점수가 약 2412정도로 나왔다. SGD의 기본 threshold는 0이기 때문에 2412 > 0 식이 만들어지게 되고, True이기 때문에 올바르게 예측한 것으로 나오게 된다. Threshold를 8000으로 설정하게 되면 False가 된다, recall이 낮아진 것이다. 실제로 5지만, threshold를 높혔을 때 classifier가 제대로 예측을 못하게 된 것이다.
그렇다면 언제 어떤 값의 threshold를 사용해야 하는지 궁금해진다.
언제 어떤 값의 threshold를 사용하는지 알기 위해서 먼저 threshold의 변화에 따라서 precision과 recall이 어떻게 변화는지 알아야 한다. 먼저 cross_val_predict()를 사용해서 instance별로 점수를 얻은 다음에 threshold에 따라서 어떻게 변화하는지 precision_recall_curve()를 사용해서 볼 수 있다.
from sklearn.metrics import precision_recall_curve
y_scores = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3, method="decision_function")
precisions, recalls, thresholds = precision_recall_curve(y_train_5, y_scores)
# 시각화...
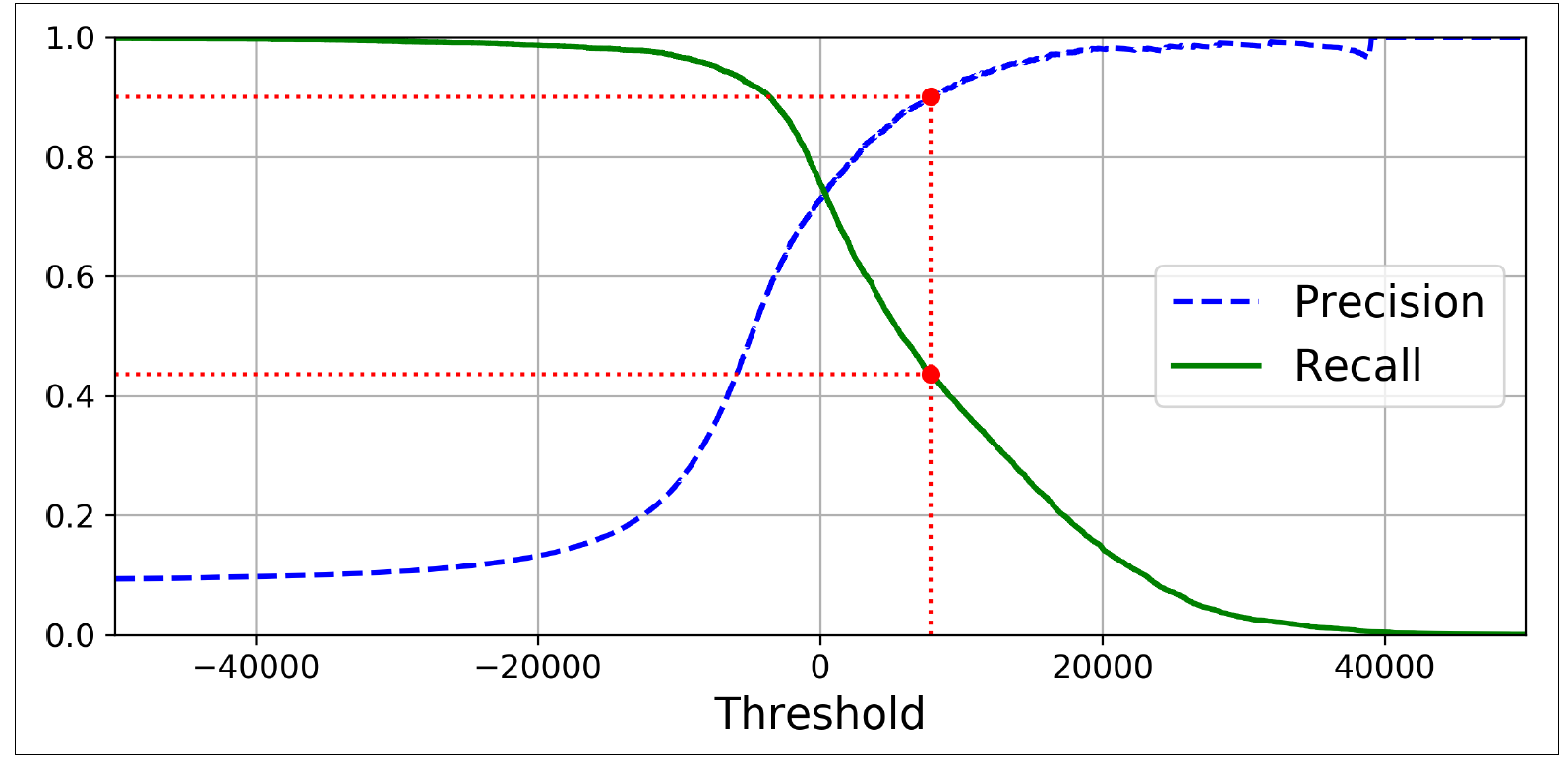
90%의 precision을 원할 때 recall은 43%정도가 되는 것을 볼 수 있다. Precision과 recall의 상관관계를 더 확실하게 보고 싶으면 직접 비교를 하는 것도 좋은 방법이다.
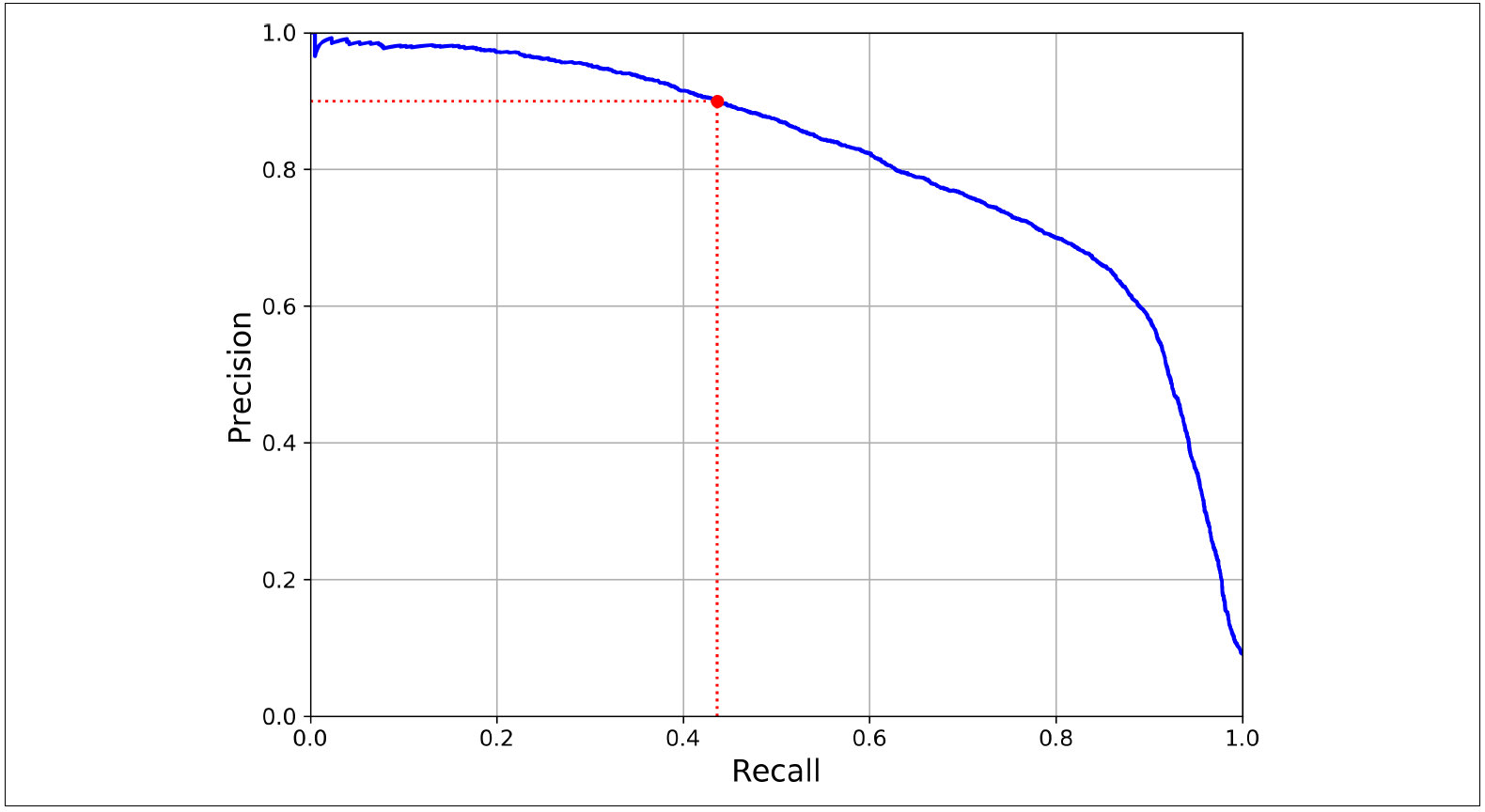
Precision과 Recall의 상관관계를 바로 나타낸 그래프를 보면, recall이 높아짐에 따라서 precision이 급격하게 줄어드는 것을 볼 수 있다. Precision이 급격하게 떨어지는 구간 전을 threshold를 선택하는 것이 좋다. 예를 들어, 90% precision을 원할 때 낮은 threshold 중에서 최소 90%의 precision을 보이는 값을 선택하면 된다.
3.3.3 The ROC Curve
Receiver Operating Characteristic (ROC) curve는 binary classifier와 자주 쓰이는 툴이다. Precision/recall curve와 비슷하지만 true positive rate(recall) vs false positive rate를 계산한다. FPR은 negative instance들이 positive로 잘못 분류된 비율을 의미한다. 즉, 5가 아닌 숫자들을 5로 분류한 경우들이다.
from sklearn.metrics import roc_curve
fpr, tpr, thresholds = roc_curve(y_train_5, y_scores)
# 시각화...
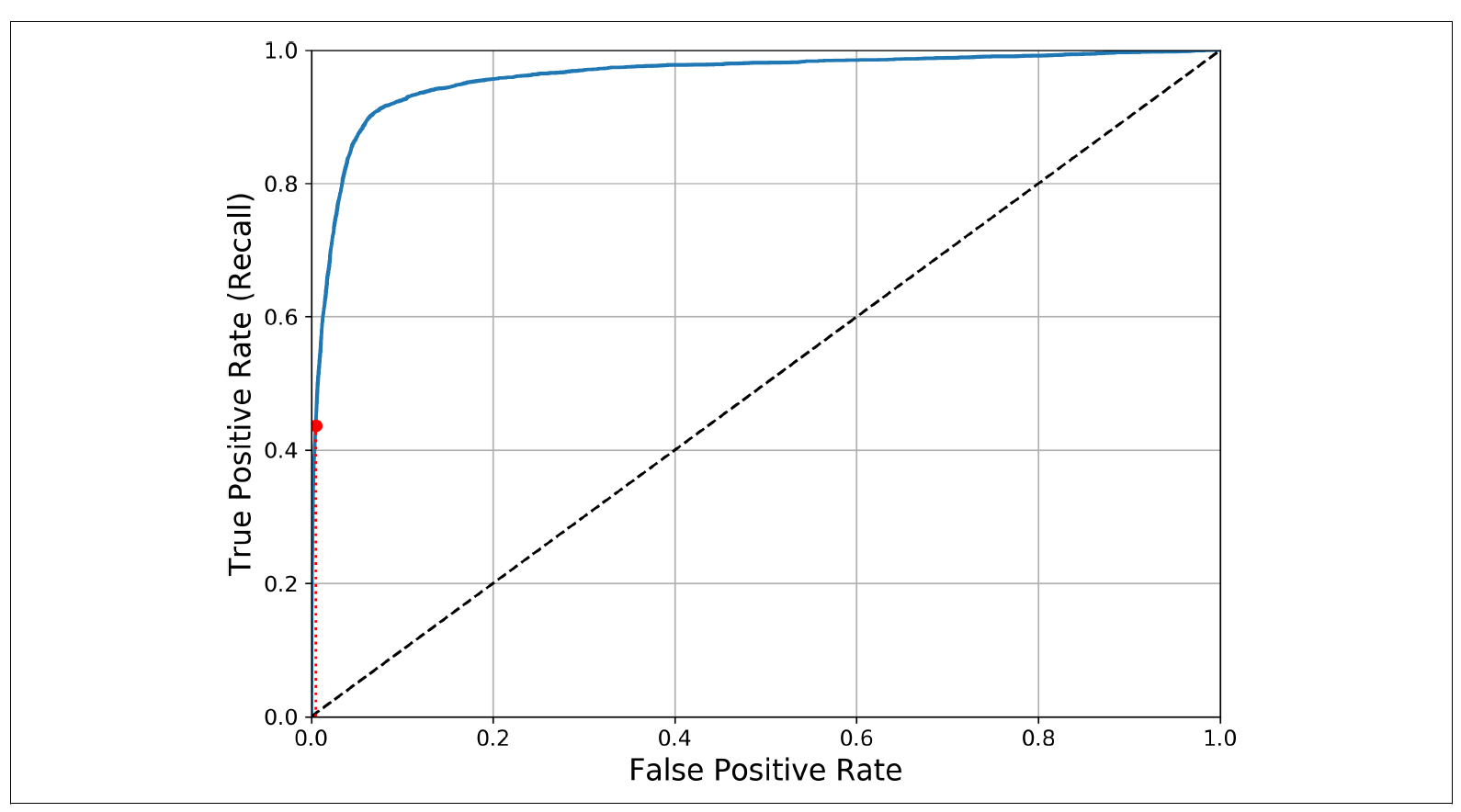
여기서도 tradeoff가 발생한다. TPR(recall)이 높을 수록 FPR(false positives)도 높아진다. 중간에 점이 있는 선은 랜덤한 classifier를 의미한다, 중간 선에서 멀어질수록 좋은 classifier라고 볼 수 있다. 완벽한 classifier일수록 1에 가깝고 random한 classifier일 수록 0.5에 가깝다.
from sklearn.metrics import roc_auc_score
roc_auc_score(y_train_5, y_scores)
# 0.961177xxxx
ROC curve가 precision/recall curve와 비슷하기 때문에 어떤 방법을 사용해야 하는지 헷갈릴 수 있는데, 어떤 문제에 초점을 더 두는지에 따라서 선택을 하면 된다. Positive class가 적던지 false positive에 더 초점을 드면 precision/recall curve가 낫고, false negative에 초점을 두면 ROC가 낫다.
3.4 Multiclass Classification
지금까지 5와 5가 아닌 숫자들을 분류하는 binary classifier에 대해 얘기를 했다. 하지만, 본래 MNIST문제는 이미지를 0~9를 분류하는 multiclass classification 문제이기 때문에 조금 다르게 접근을 해야 한다.
Multiple binary classifiers
Binary classifier 여러개 사용해서 multiclass classifier를 만들 수도 있다. 예를 들어, 1-detector, 2-detector…등을 만들고 그 중 가장 높은 decision score를 가진 detector를 골라서 이미지를 분류할 수 있다. 이 과정을 one-versus-all(OvA)라고 부른다. 다른 방법로는, 0과 2 분류 detector, 1과 2 분류 detector 등을 만들어서 분류하는 방법이 있고, one-versus-one (OvO)라고 불린다. Class의 개수에 따라 필요한 classifier의 수도 달라진다. N개의 class가 있으면 N * (N-1) / 2 개의 classifier가 필요하게 된다, 우리의 MNIST 문제의 경우에는 총 45개의 classifier가 필요하게 된다.
OvA와 OvO의 장단점은 확연하게 다르다. OvO의 경우에는 각 classifier가 2개의 class에 속한 training set들에만 학습되면 된다. 그래서 training set가 적어도 괜찮은 결과를 만들어낼 수 있다, SVM이 이러한 종류중 하나이다. 하지만 일반적으로 binary classification을 할 떈는 OvA가 선호된다.
Scikit-Learn은 기본적으로 binary classsification을 할 떄 OvA 방식으로 진행을 한다 (SVM일 때는 OvO).
sgd_clf.fit(X_train, y_train)
sgd_clf.predict([digit])
# array([5], dtype=uint8)
digit_scores = sgd_clf.decision_function([digit])
digit_scores
# array([-15955.xxx,...,2412.5317xxx,...])
np.argmax(digit_scores)
# 5
sgd_clf.classes_
# array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=unit8)
sgd_clf.classes_[5]
# 5
SGDClassifier가 내부적으로 어떻게 작동하는지 설명해보려고 한다. SGDClassifier는 10개의 binary classifier들을 만든 다음에 각각 decision 점수들을 뽑아온 다음에 가장 큰 값을 선택하고 보여준다.
기본적으로 classifier마다 OvO인지 OvA인지 정해져있지만, 임의로 OneVsOneClassifier 혹은 OneVsRestClassifier를 사용해서 방식을 변경할 수 있다.
Multiclass classifier
RandomForestClassifier는 여러 class들을 한번에 classify 할 수 있기 때문에 OvA나 OvO 방식을 사용하지 않는다. predict_proba()를 사용해서 instance마다의 확률을 구할 수 있다.
# Random Forest
forest_clf.fit(X_train, y_train)
forest_clf.predict([digit])
forest_clf.precit_proba([digit])
# [[0., 0., 0.01, 0.08, 0., 0.9, 0., 0., 0., 0.01]]
주어진 이미지가 90%의 확률로 5일 것으로 나왔고, 그 이미지가 2, 3, 9일 확률은 각각 1% 8% 1%로 나왔다. 5일 확률이 가장 높기 때문에 주어진 이미지는 5라고 결론 짓게 되는 것이다.
Classifier를 평가할 때, cross evaluation을 사용하면 된다.
cross_val_score(sgd_clf, X_train, y_train, cv=3, scoring="accuracy")
# array([0.84xx, 0.87xx, 0.86xx])
정확도를 높히고 싶으면 input을 scaling하기만 해도 높일 수 있다.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train.astype(np.float64))
cross_val_score(sgd_clf, X_train_scaled, y_train, cv=3, scoring="accuracy")
# array([0.89xx, 0.89xx, 0.90xx])
3.5 Error Analysis
문제에 적합한 모델을 찾고 학습을 하고나서도 해당 모델의 성능을 향상시킬 필요가 있을 때가 있다. 그럴 때는 에
러를 분석해서 방법을 찾을 수 있다.
Confusion matrix를 보면서 어떤 에러들이 일어나고 있는지 확인할 수 있다.
y_train_pred = cross_val_predict(sgd_clf, X_train_scaled, y_train, cv=3)
conf_mx = confusion_matrix(y_train, y_trian_pred)
print(conf_mx)
# [[5578, 0, 22, 7, 8, 45, 35, 5, 222, 1],
# [0, 6410, 35, 26, 4, 44, 4, 8, 198, 13],
# [28, 27, 5232, 100, 74, 27, 68, 37, 354, 11],
# [23, 18, 115, 5254, 2, 209, 26, 38, 373, 73],
# [11, 14, 45, 12, 5219, 11, 33, 26, 299, 172],
# [26, 16, 31, 173, 54, 4484, 76, 14, 482, 65],
# [31, 17, 45, 2, 42, 98, 5556, 3, 123, 1],
# [20, 10, 53, 27, 50, 13, 3, 5696, 173, 220],
# [17, 64, 47, 91, 3, 125, 23, 11, 5421, 48],
# [24, 18, 29, 67, 116, 39, 1, 174, 329, 5152]])
plt.matshow(conf_mx, cmap=plt.cm.gray)
plt.show()
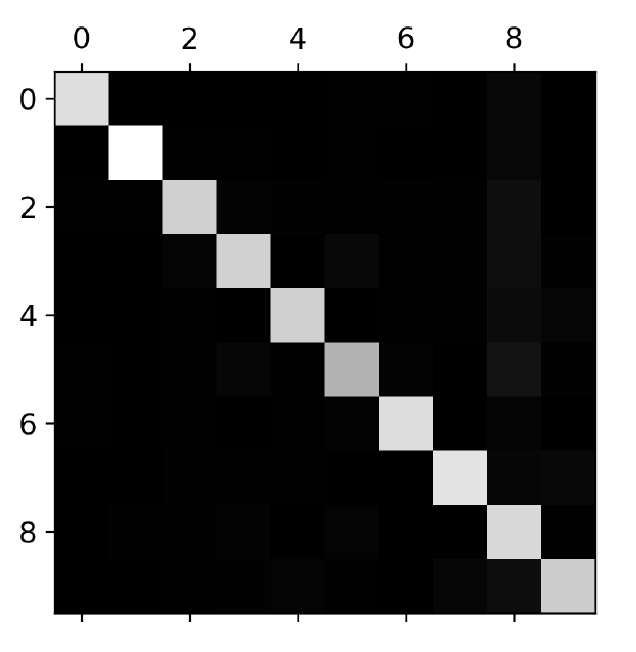
Confusion matrix를 시각화하면 위와 같은 그림을 얻을 수 있다. 대각선이 밝기 때문에 대부분은 분류가 잘 되고 있다, 하지만 5 부분을 자세히 보면 다른 부분들보다 조금 어둡다. 이는 5의 data가 적던지 classifier가 5에 대해 좋지 않은 성능을 보인다는 것을 의미한다.
Error rate를 구해서 보다 정확하게 어떠한 부분에 대해서 classifier가 잘못 분류를 하는지 확인해볼 수 있다. Confusion matrix에 있는 값들을 각 값들의 이미지 숫자로 나눠서 알 수 있다.
row_sums = conf_mx.sum(axis=1, keepdims=True)
norm_conf_mx = conf_mx / row_sums
np.fill_diagonal(norm_conf_mx, 0)
plt.matshow(norm_conf_mx, cmap=plt.cm.gray)
plt.show()
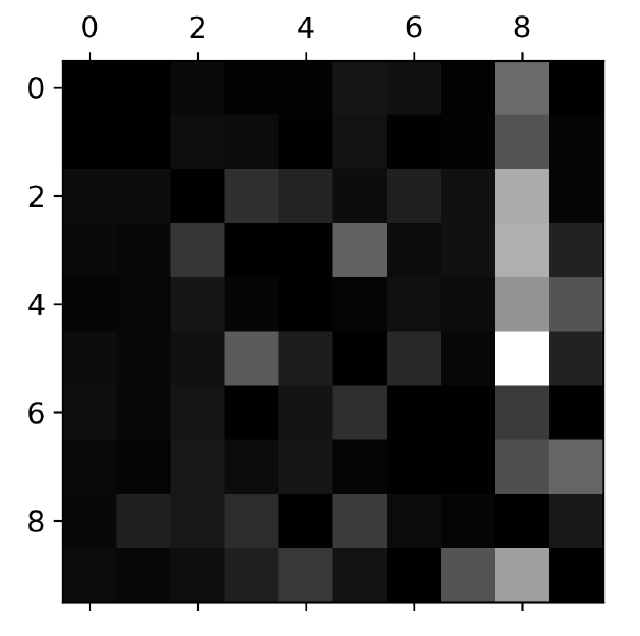
이제 더 확실하게 classifier가 어떤 error를 만들어내는지 볼 수 있게 되었다. row가 실제 class를 의미하고 column은 예측된 class를 의미한다. 8 column이 밝은 것을 볼 수 있는데 이는 많은 이미지들이 8로 잘못 분류되었다는 것이다. Row 8은 검정색에 가깝기 때문에 8은 8로 잘 분류되었음을 의미한다. 5와 3도 보면 서로 잘 헷갈리는 것도 볼 수 있다. [5,3][3,5]
이처럼 어떤 data에 대해서 어떤 에러가 발생하는지 알게 되면 classifier를 어떻게 더 학습시킬 것인가에 대한 생각을 할 수 있게 된다. 이 dataset의 경우에는 8 데이터를 더 받아와서 학습시키던지 8과 2,3,5,9 등을 구분할 수 있는 특징들을 추출해와서 새로 학습시킬 수도 있다.
3과 5, 5와 8등이 비슷하게 분류된 이유는 SGDClassifier를 사용했기 때문이다. SGDClassifier는 linear model이다. 이 classifier가 하는 것은 class마다 다르게 각 픽셀에 weight를 지정해줘서 학습을 하는 것이다. 3과 5같은 경우는 픽셀차이가 크지 않기 때문에 모델이 헷갈려 하는 것이다. 3과 5의 결정적인 차이는 위 라인이 왼쪽에 있냐 혹은 오른쪽에 있냐인데, SGD는 픽셀의 차이만 보기 때문에 방향과 위치에는 무감각하다. SGDClassifier를 사용하는 경우에 에러를 줄이기 위해서는 이미지가 정확히 중간에 오게 하고 회전같은 transformation이 많으면 안된다.
3.6 Multilabel Classification
MNIST dataset은 하나의 입력에서 하나의 결과만 나오게 된다. 하지만, 실제 문제에서는 한 입력에서 여러개의 class들을 추출해야 하는 경우가 있을 수 있다. 한 이미지에서 고양이, 개, 말들을 인식하는 경우가 하나의 예이다. 그림 A에 고양이와 개가 있으면 [1,1,0], 그림 B에서 말만 개만 있다면 [0,1,0] 이러한 예측된 결과가 보여져야 한다.
조금 더 간단한 문제를 풀어보려고 한다. 숫자 이미지가 주어졌을 때 해당 이미지내에 있는 숫자의 값이 큰지 (7이상) 혹은 홀수인지 확인하려고 한다. 각각 조건에 해당하는 training set을 확보한 다음에 KneighborsClasssifier를 사용해서 여러 label들을 동시에 학습한다.
from sklearn.neighbors import KNeighborsClassifier
y_train_large = (y_train >= 7)
y_train_odd = (y_train %2 == 1)
y_multilabel = np.c_[y_train_large, y_train_odd]
knn_clf = KNeighborsClassifier()
knn_clf.fit(X_train, y_multilabel)
knn_clf.predict([digit])
# array([[False, True]])
5는 크지 않고 (False) 그리고 홀수(True)이기 [False, True]라는 결과가 나오게 된다.
Multilabel classifier를 평가하는 방법도 여러가지가 있고, F1 score로도 평가를 할 수 있다. 각각 독립적인 라벨당 F1 score를 구한 다음에 평균 점수를 계산한다.
y_train_knn_pred = cross_val_predict(knn_clf, X_train, y_multilabel, cv=3)
f1_score(y_multilabel, y_train_knn_pred, average="macro")
# 0.97641xxxx
기본적으로 모든 label들에 동일한 weight를 부여한다. 만약 특정 label에 더 많은 weight를 주려면 average="weighted"로 바꾸면 된다.
References
Random State
Cross-validation
- https://nonmeyet.tistory.com/entry/KFold-Cross-Validation교차검증-정의-및-설명
- https://3months.tistory.com/321
F-score & harmonic mean
Subscribe via RSS
{kind=link}