[핸즈온 머신러닝-2] ML 프로젝트는 어떻게 진행되는가
by Dojin Kim
Hands On ML
핸즈온 머신러닝 영어 PDF를 읽고 공부하면서 내용을 정리하고 있다. 정리에 나온 대부분의 코드와 이미지들은 해당 PDF에서 가져왔다.
Chapter 2 - End-to-End Machine Learning Project
[핸즈온 머신러닝] 2장에서는 필드에서 일하는 데이터 사이언티스트라면 어떻게 문제를 바라야하고, 생각하고, 해결해야하는지에 대해 설명을 한다. 모든 코드들과 내용을 다루지는 않고 크게 어떻게 문제 제기부터 해결까지 데이터 사이언티스들이 진행하는지 알아볼 예정이다.
실제 데이터를 얻는 것은 매우 어려운 일이지만, 다행히도 이러한 데이터를 제공해주는 곳이 몇 군데 있다:
- Open data 레포지토리들:
- 포탈들
- 다른 open data 레포지토리들을 소개해주는 사이트들
책에서는 1990년 캘리포니아 집값 dataset을 사용했다.
2.1 Look at the Big Picture (큰 그림으로 문제 바라보기)
Step 1) Dataset이 주어지면 가장 먼저 해야 하는 것은 분석의 목적이 무엇인지 파악하는 것이다. 분석 모델을 어떻게 사용할 것이고 어떠한 benefit을 얻기를 원하는지 알아야 한다. 이러한 목표를 분명하게 알아야지 데이터 사이언티스트는 목표에 적합한 알고리즘을 선택할 수 있게, 어떤 방식으로 evaluate(평가)를 할지 정할 수 있게 된다. **
회사의 보스가 주어진 dataset으로 만들어진 모델이 특정 지역의 집값의 중간값을 예측하기를 원한다고 가정하고 문제를 풀어나가보려고 한다.
Step 2) 그 다음에 해야할 질문은, “현재는 문제를 어떻게 해결하고 있는가?” 이다. 현재 어떻게 해결 중인지를 알면 나중에 모델의 성능을 비교할 때 참고할 수 있고, 문제를 해결하기 위한 인사이트를 얻을 수 있다.
현재는 전문가들이 일일이 지역의 집값을 측정한다고 가정해보자. 현재의 해결책은 사람이 발로 뛰어다니면서 알아보기 때문에 expensive하고 time-consuming하다.
Step 3) 이 처럼 문제가 무엇이고 현재에는 어떻게 해결하는지 파악하면 어떤 방식으로 문제를 풀어나갈 지 정리를 할 수 있게 된다. Dataset으로 labelling된 데이터들이 주어졌기 때문에 supervised 방식을 사용하고, 값을 예측해야 하기 때문에 regression문제 임을 알 수 있다. 또한, 집값 예측을 위해 여러 개의 feature(특징)들이 주어졌기 때문에 multiple regression문제 임을 알 수 있다. 각 지역마다 하나의 값만 예측하려고 하기 때문에 univariate regression문제이다. 마지막으로, data가 실시간으로 변화하지 않고 dataset의 크기도 작기 때문에 batch learning으로 해도 나쁘지 않다. 분석하는 목표와 dataset의 특징들을 보면서 문제가 어떤 유형에 속하는지 알 수 있고 분석을 계획할 수 있게 된다.
Step 4) Perfromance Measure 선택하기. Regression 문제에서 전형적으로 사용되는 performance measure(성능 측정)은 Root Mean Square Error(RMSE)이다. 예측을 할 때 얼마만큼의 에러가 발생하는지 알 수 있다. 수학식은 다음과 같다:
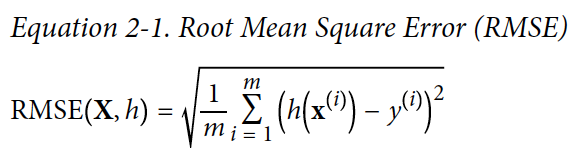
Performance maesuare 할 때 RMSE가 자주 사용되지만, outlier(평균을 왜곡시키는 맨 끝 값들)가 많은 경우에는 Mean Absolute Error (MAE)를 사용하는게 나을 수가 있다.
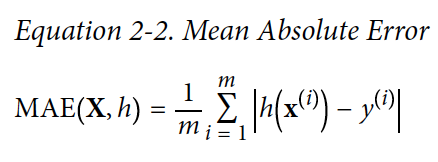
2.2 데이터 가져오기
Jupyter notebook을 설치해서 사용하고 있다
# 첫 5개 row를 보여준다
housing.head()
# data길이, 각 attribute들의 type, non-null value의 수를 보여준다
housing.info()
# count, mean, max 등에 대한 정보를 보여준다
housing.describe()
housing에는 dataset을 table형태로 저장이 되어있다. head()는 dataset의 첫 5개의 row만 보여주는 method이다. info()는 각 attribute들의 type을 보여준다, DB에서 name VARCHAR(100)와 비슷하다. describe()는 전체 dataset에 대해 count, mean, max등의 정보를 보여준다.
Sklearn
모델을 만들기 위해서는 모델을 train, test set으로 나눠서 학습을 시키고 evaluation(평가)를 해야 한다. 일일이 어떤 data는 training set에 두고 어떤 data는 test set에 직접 넣는 것은 매우 노가다이기 때문에, sklearn를 사용하는 것이 가장 쉬운 방법이다. sklearn는 train과 test dataset을 랜덤하게 자동으로 나누는 train_test_split 함수를 제공한다.
from sklearn.model_selection import train_test_split
train_set, test_set = train_test_split(housing, test_size=0.2, random_state=42)
위는 완전 순수한 랜덤 샘플링 방법이다. Dataset이 클 때는 적절한 방법이지만, dataset이 작으면 샘플링 bias가 생길 가능성이 높다. Dataset이 작을 때는 stratified sampling을 사용해서 bias없이 dataset을 나눌 수 있다. 예를 들어, 미국 국민의 51.3%가 여자고 48.7%가 남자라면, 1000명을 샘플링할 때 비율에 맞게 여자 513명 남자 287명으로 나누는 것이다. 실제 dataset가 비슷한 비율로 샘플을 가져오기 때문에 bias를 없앨 수 있고, 랜덤하게 샘플링한 것보다 dataset을 더 잘 나타낸다.
2.3 ML알고리즘을 위해 데이터 준비하기
수동으로 dataset을 ML 알고리즘에 넣는 대신에 함수를 작성해야 한다, because:
- 어떤 dataset에던지 transformation을 가능하게 해준다
- 나중에 reuse할 수 있는 transformation function의 library를 빌드할 수 있게 된다.
- 알고리즘에 feeding하기 전에 live system에 새로운 data transform 가능
- 다양한 transformation 가능해진다
Data Cleaning
ML 알고리즘 모델을 구현하기 전에 데이터를 정리해야 한다. 대부분의 ML 알고리즘들은 feature가 빠져있으면 제대로 작동하지 않는다 (e.g. null 값들). 캘리포니아 dataset의 경우에는 total_bedrooms 값이 없는 지역이 있었다. 만약 빠져있는 (missing) feature들이 있으면 3가지 방법으로 수정을 할 수 있다:
- Missing 값이 있는 지역 dataset에서 제거
total_bedrooms라는 attribute 전체 제거- Missing 값들을 임의로 특정한 값을 준다. (e.g. 0, 평균값, 중간값….)
3번 방법을 사용하고 missing값들을 중간값으로 채워 놓아보자. Missing 값들을 다루는 Scikit-Learn의 SimpleImputer라는 함수를 사용하면 된다.
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy="median")
Median 값의 문제는 숫자만 연산 가능하다는 것이다. 하지만, 우리가 갖고 있는 dataset에는 text로 되어있는 ocean_proximity라는 attribute가 있기 때문에 제거를 해야 한다. 제거를 한 후에 fit method를 사용해서 missing 값들을 채워놓으면 된다. imputer는 각 attribute의 median을 구하고, statistics_라는 인스턴스 변수에 값을 저장한다.
# ocean_proximity attribute 제거
housing_num = housing.drop("ocean_proximity", axis=1)
imputer.fit(housing_num)
print(imputer.statistics_)
# array([-118/51. 34/26, 29., 2119.5, 433., 1164., 408., 3.5409])
Text 다루기
위에서 missing 값들을 채우기 위해 text로 이뤄진 ocean_proximity attribute을 제거했었다. 하지만, 해당 attribute도 분석을 하는 것에 있어서 필요한 data이기 때문에 ML 알고리즘에서 사용하기 용이하게 text를 숫자로 변환을 해줘야 한다.
Scikit-Learn의 OrdinalEncoder를 사용해서 text들을 숫자로 변환할 수 있다.
from sklearn.preprocessing import OrdinalEncoder
ordinal_encoder = OrdinalEncoder()
housing_cat_encoded = ordinal_encoder.fit_transform(housing_cat)
housing_cat_encoded[:10]
# array([[0.],[0.],[4.],[1.],[0.], [1.],[0.],[1.],[0.],[0.]])
ordinal_encoder.categoreis_
# [array(['<1H OCEAN', 'INLAND', 'ISLAND', 'NEAR BAY', 'NEAR OCEAN'],dtype=object)]
Text로 되어있었던 값들이 숫자로 변환이 되었고, 같은 숫자면 같은 값을 의미한다. 각 숫자 값들이 어떠한 text를 의미하는지 보기 위해서는 categories_라는 instance 변수로 볼 수 있다.
하지만, text를 숫자로 변환하면 한가지 문제가 발생한다. 일반적으로는 숫자들의 값이 서로 가까우면 비슷하다고 간주를 한다. 예를 들어, 소비자 만족 평가 같은 곳에서 4,5는 좋은 반응이라고 여기고, 3은 보통, 1,2는 별로라고 여긴다. 그러나, OCEAN, INLAND, ISLAND 등의 text 값들은 숫자로 변환이 되긴 했지만 서로 비슷한 값이라고 보기는 힘들다.
이러한 상황에서는 카테고리별로 binary attribute 하나를 만들어야 한다. 이 과정을 one-hot encoding 이라고 부른다. (0~5) 처럼 연속적인한 값이 아니라, 값이 1(Hot)이던지 0(Cold)이다. 예를 들어, 카테고리 <1H OCEAN의 값이 1이면 나머지는 다 0인 것이다.
# OneHotEncoder class는 카테고리 값을 one-hot 벡터로 변환한다
from sklearn.preprocessing import OneHotEncoder
cat_encoder = OneHotEncoder()
housing_cat_hot = cat_encoder.fit_transform(housing_cat)
하나 알아놔야 할 점은 리턴되는 값이 numpy array가 아닌 sparse matrix 형태라는 것이다. One-hot encoding을 사용하면 category 수만큼의 컬럼을 가진 행렬을 얻게 된다. 이 행렬에서 하나(hot) 빼고 나머지는 다 0으로 채워져있다. 예를 들어, 카테고리가 5개인 data가 있으면 [0, 0, 0, 1, 0] 이런 형식으로 결과가 나오게 되는 것이다. 카테고리가 수천개, 수만개여도 1은 오직 하나밖에 없고 나머지는 다 0이기 때문에 메모리를 많이 잡아먹는 비효율적인 구조인 것이다.
그래서 sprase matrix는 0이 아닌 값의 위치만을 저장하고 있다. [0, 0, 0, 1, 0]인 행렬이 있으면 행렬 내 위치인 ‘3’만 저장하는 것이다. 이렇게 하면 메모리 사용을 줄일 수 있게 된다.
Feature Scaling
Dataset을 정리할 때 feature scaling은 가장 중요한 transformation이다. 몇몇 예외사항을 제외하고 입력 값들이 많이 다른 scale을 가지고 있을 때 ML 알고리즘이 제대로 작동 안한다 (e.g room 수의 범위 - 6~39320, 수입 중간값 0~15). 여러 attribute들을 동일한 scale로 만드는 방법으로는 2가지가 있다:
- min-max scaling
- standardization
Min-max scaling(normalization이라고도 불림)의 아이디어는 간단하다. 값들이 shift되고 rescale되서 0~1사이의 범위를 가지게 된다. min 값을 빼고 (max-min) 값으로 나누면 된다. Scikit-Learn에서 MinMaxScaler를 제공한다. 항상 0~1 범위를 가지는 것은 아니다, feature_range라는 hyperparameter의 값을 변경해서 범위를 수정할 수도 있다.
Standradization은 처음에 mean 값을 뺀 다음에 standard deviation(표준편차)으로 나눠서 distribution(분산)이 unit variance(단위분산)를 갖게 한다. Standardization은 특정한 범위에 제한되지 않는다. 그래서 보통 outlier들에 덜 영향을 받는다. Scikit-Learn의 StandardScaler를 사용해서 standardization을 할 수 있다.
2.4 Model 학습 및 선택하기
Training set 학습 및 평가
- Linear Regression model 만드는 것은 scikit-learn 덕분에 쉽게 할 수 있다.
from sklearn.linear_model import LinearRegression
lin_reg = LinearRegression()
lin_reg.fit(housing_prepared, housing_labels)
some_data = housing.iloc[:5]
some_labels = housing_labels.iloc[:5]
some_data_prepared = full_pipeline.transform(some_data)
print("Predictions:", lin_reg.predict(some_data_prepared))
# Predictions: [ 210644.6045 317768.8069 210956.4333 59218.9888 189747.5584]
print("Labels:", list(some_labels))
# Labels: [286600.0, 340600.0, 196900.0, 46300.0, 254500.0]
예측은 됐지만, 매우 낮은 정확도가 나왔다. 이제 전체 training set을 RMSE에 넣어보자
from sklearn.metrics import mean_squared_error
housing_predictions = lin_reg.predict(housing_repared)
lin_mse = mean_squared_error(housing_labels, housing_predictions)
lin_rmse = np.sqrt(lin_mse)
lin_rmse
# 68628.19819848922
median_housing_value가 ($120,000 ~ $265,000) 인데 $68,628 error가 발생했다. 예측값의 오차가 68,628이라는 뜻인데 범위에 비해 너무 크다. 에러를 보면 underfitting이 발생한 것을 알 수 있다. Underfitting을 해결하기 위한 방법 중 하나는 더 나은 모델을 선택하는 것이다.
- 이번에는
DecisionTreeRegressor로 학습을 해보자. 해당 모델을 linear하지 않은 관계를 찾는데 적합하다.
from sklearn.tree import DecisionTreeRegressor
tree_reg = DecisionTreeRegressor()
tree_reg.fit(housing_prepared, housing_labels)
housing_predictions = tree_reg.predict(housing_prepared)
tree_mse = mean_squared_error(housing_labels, housing_predictions)
tree_rmse = np.sqrt(tree_mse)
tree_rmse
# 0.0
error가 0이 나왔다. 0이 나왔다는 것은 모델의 예측력이 100% 정확하다는 것인데, 실제 문제에서 100%로 정확한 모델은 나오는 것이 불가능하다. 그렇기 때문에 해당 모델에 overfitting이 발생했다고 간주할 수 있다.
Cross-Validation을 사용해서 더 나은 evaluation하기
위 모델들은 train_test_split으로 train set과 test set을 나눠서 학습을 했다. 하지만, dataset 자체가 작기 때문에 Decision Tree model을 학습시켰을 때 overfitting이 발생한 것이다. Overfitting 문제를 방지하고 더 나은 evalution을 하기 위해서는 training set을 더 쪼개서 더 작은 training set들과 validation set으로 나누는 cross-validation방법이 있다.
그 중에서 우리는 K-fold cross validation을 사용하려고 한다. K-fond cross validation은 랜덤하게 training set을 n개의 subset인 fold로 나눈다. Decision tree model은 10번 학습을 하고 evaluate을 하게 된다. 학습 때마다 다른 fold를 선택하고 나머지 fold에 속하는 데이터에 학습을 한다. (n=10이라고 가정) random하게 training set을 10개의 distinct subset인 folds로 나눈다. 그러고 나서 Decision tree model을 10번 학습하고 evaluate한다. 매번 하나의 fold를 evaluation하기 위해 선택하고 나머지 9개 fold를 학습한다. 10번 반복을 하고 나면 10개의 evaluation 점수를 가진 array를 얻게 된다.
from sklearn.model_selection import cross_val_score
scores = cross_val_score(tree_reg, housing_prepared, housing_labels, scoring="neg_mean_squared_error", cv=10)
tree_rmse_scores = np.sqrt(-scores)
print(tree_rmse_scores.std())
# 2439.43450411
하지만, DecisionTree model도 성능이 그렇게 좋지 않음을 알 수 있다.
- 그래서
RandomForestRegressor를 사용해보려고 한다. RandomForset는 여러개의 Decision Tree를 random subset으로 학습시키고 예측값의 평균을 구하는 방법이다. 많은 다른 모델 위에 model을 빌드하기 떄문에Ensemble Learning이라고도 부른다.
from sklearn.ensemble import RandomForestRegressor
forest_reg = RandomForestRegressor()
forest_reg.fit(housing_prepared, housing_labels)
...
print(forest_rmse_scores.std())
# 2097.0810550
하지만 evaluation 점수를 보면 RandomForest도 overfitting을 보임을 알 수 있다. 문제를 해결하기 위해서는 모델을 더 단순화 하던지 정규화하던지 training data를 더 얻어와야 한다.
2.5 Model Fine-Tune하기
Grid Search
Model을 fine-tune하는 방법으로는 hyperparamater값을 바꾸는 방법이 있다. 수동으로 hyperparameter값들을 변경하는 것은 매우 오래걸리고 불확실한 작업이다 Scikit-learn의 GridSearchCV를 사용하면 hyperparameter들의 최적 조합을 찾을 수 있다.
from sklearn.model_selection import GridSearchCV
param_grid = [
{'n_estimators': [3, 10, 30], 'max_features': [2, 4, 6, 8]},
{'bootstrap': [False], 'n_estimators': [3, 10], 'max_features': [2, 3, 4]},]
forest_reg = RandomForestRegressor()
grid_search = GridSearchCV(forest_reg, param_grid, cv=5,
scoring='neg_mean_squared_error',
return_train_score=True)
grid_search.fit(housing_prepared, housing_labels)
param_grid는처음에 n_estimators 3과 max_features로 설정해서 12(3x4)개의 조합을 evaluate 하라고 한다. 그 다음에 6(2x3)개의 조합을 evaluate하는데, 이 때 bootstrap을 False로 설정해서 evaluate하라고 한다.
결국, 총 12 + 6 = 18개의 조합들이 RandomForestResgressor hyperparameter value로 들어가게 된다. 그리고 각 모델을 5개의 fold로 cross-validation으로 학습할 것이기 때문에 총 18x5 = 90번의 학습이 이뤄지는 것이다. 모든 학습이 다 끝나고 나서는 가장 최적의 parameter 조합을 알 수 있게 된다.
# 최적의 parameter예시
grid_search.best_params_
# {'max_features':8, 'n_estimators':30}
# 이렇게 각 combination의 evaluation score도 볼 수 있다.
cvres = grid_search.cv_results_
for mean_score, params in zip(cvres["mean_test_score"], cvres["params"]):
print(np.sqrt(-mean_score), params)
GridSearchCV를 이용해서 가장 최적의 hyperparameter를 별 어려움 없이 구할 수 있다.
Randomized Search
GridSearchCV방법은 적은 수의 조합을 구할 때는 적절하지만, hyperparamater의 수가 많을 때는 RandomizedSearchCV를 사용하는 것이 더 적절하다. 모든 조합들을 다 찾는 대신에 랜덤한 값들을 선택하는 것이다. 랜덤한 값을 찾는 것의 장점은 2가지가 있다:
- 1000 iteration을 한다고 가정했을 때, 각 hyperparameter 별로 1000개의 다른 value들을 찾을 수 있게 된다.
- Iteration의 수를 설정할 수 있기 때문에 메모리 관리나 컴퓨팅 파워를 조절할 수 있다.
Best Model과 에러 분석
RandomForestRegressor를 사용해서 어떠한 attribute가 전체 예측 정확도를 높히는데 더 중요한 역할을 하는지 알 수 있다.
feature_importances = grid_search.best_estimator_.feature_importances_
# importance score도 attribute 이름 옆에 나타나게 할 수 있다.
extra_attribs = ["rooms_per_hhold", "pop_per_hhold", "bedrooms_per_room"]
cat_encoder = full_pipeline.named_transformers_["cat"]
cat_one_hot_attribs = list(cat_encoder.categories_[0])
attributes = num_attribs + extra_attribs + cat_one_hot_attribs
sorted(zip(feature_importances, attributes), reverse=True)
# [(0.366xxx, 'median_income'), (0.1647xxx, 'INLAND'), (0.1087xxx, 'pop_per_hhold')...]
이러한 정보들을 알게 되면 모델의 정확도에 영향일 가장 덜 주는 feature들을 제거할 수도 있다. 다음에 왜 일어나는지 이해하고 해당 문제를 해결할 수 있어야 한다.
Test Set에 evaluate하기
모델이 training set에 충분히 학습되고 나면 test set에 모델을 evaluate해야 한다.
final_model = grid_search.best_estimator_
X_test = strat_test_set.drop("median_house_value", axis=1)
y_test = strat_test_set["median_house_value"].copy()
X_test_prepared = full_pipeline.transform(X_test)
final_predictions = final_model.predict(X_test_prepared)
final_mse = mean_squared_error(y_test, final_predictions)
final_rmse = np.sqrt(final_mse)
튜토리얼 마무리하며
이 튜토리얼은 데이터 사이언티스트가 데이터를 분석하고 모델링을 해야 하는 상황에서 어떻게 문제에 접근하고 고민을 하고 풀어나가는지 간략하게 소개한 튜토리얼이다. 중간 중간에 시각화나 코드에 대한 설명들을 많이 제외했지만, 최대한 중요한 부분들은 유지했다.
Subscribe via RSS
{kind=link}