[핸즈온 머신러닝-1] Batch vs Online 학습 / Instance vs Model 기반 학습 / Testing & Validating
by Dojin Kim
Hands On ML
핸즈온 머신러닝 영어 PDF를 읽고 공부하면서 내용을 정리하고 있다. 정리에 나온 대부분의 코드와 이미지들은 해당 PDF에서 가져왔다.
Chapter 1 - Part 2
Batch and Online Learning
Batch Learning
시스템은 incrementally 학습을 할 수 없고, 모든 데이터들을 가용해서 학습을 한다. 하지만, 이 방법은 매우 느리고 많은 컴퓨터 자원을 필요로 한다. 처음에 시스템이 학습을 하고 나서 production에 들어가서 더 이상 학습을 하지 않고 run하는 것을 offline learning이라고 부른다.
이러한 시스템에서 새로운 데이터를 학습하고 싶으면 전체 데이터셋을 다시 학습해야 한다.
Online Learning
Online learning에서는 시스템이 incrementally 학습을 한다. Data를 순차적으로 feed한다(독립적으로 하나씩 혹은 mini-batch라고 불리는 작은 그룹씩).
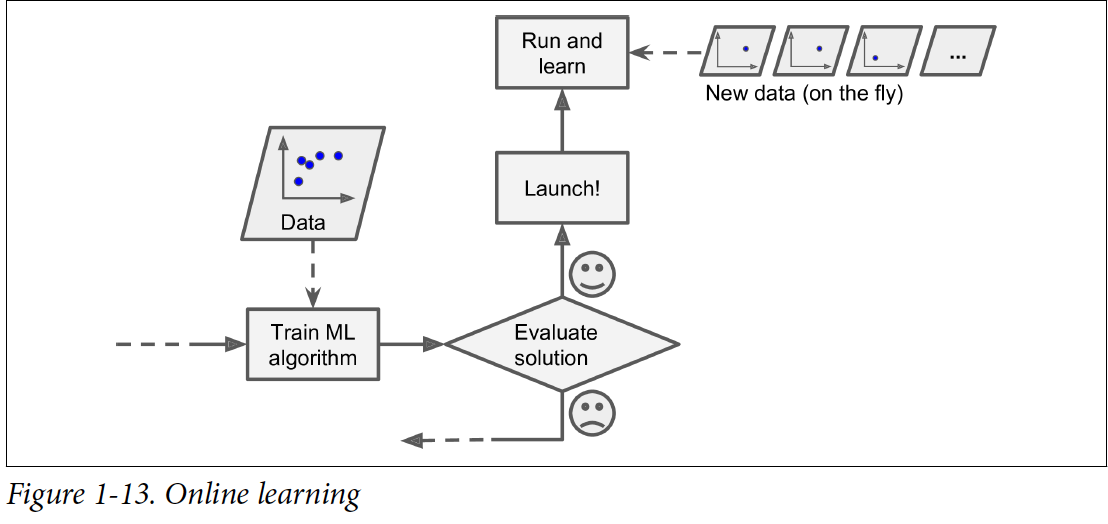
Continuous flow로 데이터를 받을 때나, 변경사항에 빠르게 적응해야 하는 시스템, 컴퓨터 자원이 부족할 때에 online learning이 적합한 학습 방법이다.
Online learning system에서 중요한 parameter는 변화하는 데이터에 얼마나 빠르게 적응하냐에 대한 것이다(Learning Rate). Learning rate 높으면 새로운 데이터에 빠르게 적응하나, 옛 데이터를 금방 잊게 된다. 반면에 learning rate낮으면 시스템이 제대로 안 배우게 된다.
Online Learning 문제점
좋지 않은 data가 feed되면 시스템의 퍼포먼스가 점진적으로 하락하게 된다. 이러한 risk를 줄이기 위해서는 시스템을 계속 모니터해야 한다.
Instance-Based VS Model-Based Learning
어떻게 generalize(일반화) 하느냐에 따라서 머신러닝 시스템을 categorize할 수 있다.
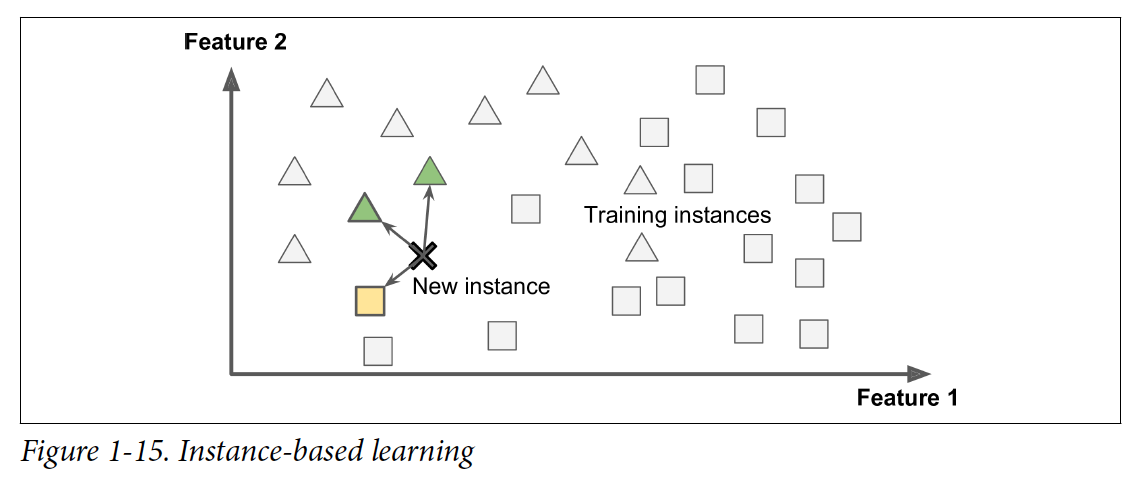
Instance-based learning
시스템이 예시들을 배운 다음에 새로운 케이스를 기존 예시들과 비교해서 generalize하는 것을 Instance-based learning이라고 한다.
Model-based learning
Example들로 model을 만든 다음에, 그 모델이 prediction을 하게 만드는 것이 model-based learning이다.
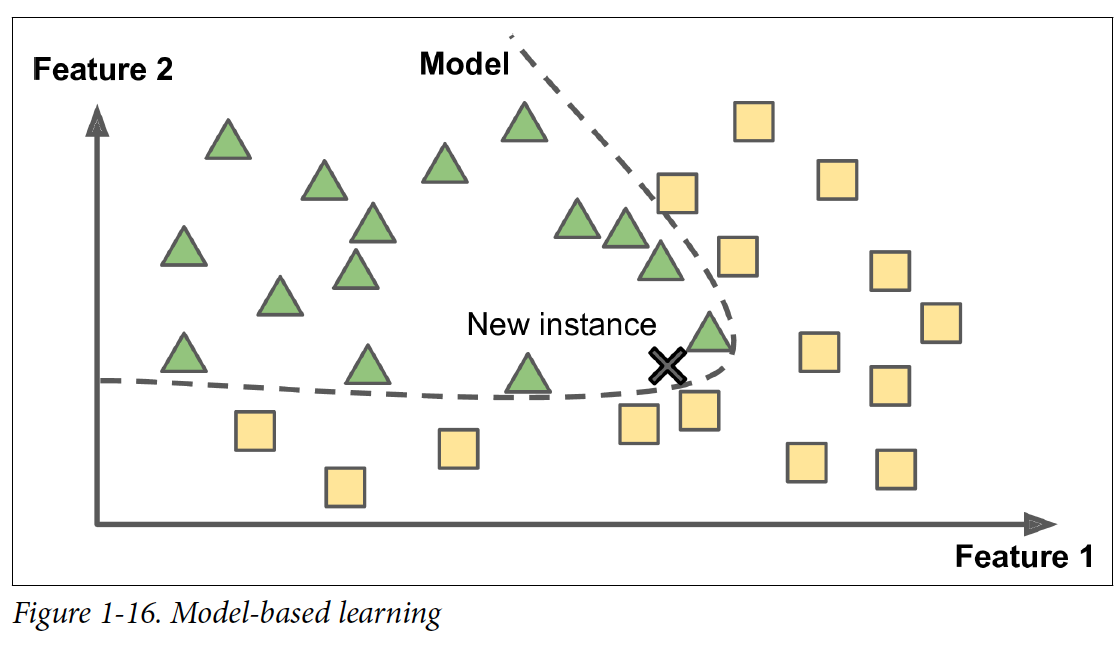
Model을 사용하기 전에 parameter value들을 정의 해야 한다. Utility function(or fitness function)을 사용해서 모델이 얼마나 good인지에 따라 정의하는 방법도 있고, cost function을 사용해서 얼마나 bad인지에 따라 정의하는 방법이 있다.
Linear regression 문제의 경우에는 보통 cost function을 사용한다, linear model의 prediction과 training example의 거리를 계산후 최소화하는 방법을 찾는다. Linear regression 알고리즘을 사용하면 parameter를 조절해서 data를 가장 잘 fit하는 방법을 찾는다.
Testing and Validating
Train set, Test set 나눈다. 새로운 case에서의 에러는 generalization error라고 불린다.
Hyperparameter Tuning and Model Selection
Overfitting을 방지하기 위해서 holdout validation을 사용하는 것이 일반적인 해결책이다. Training set의 부분을 hold out해서 여러 후보 모델들을 평가하고 가장 나은 것을 선택한다. 새로운 heldout set을 validation set이라고 부른다. 여러 모델들에 다양한 hyperparameter들을 (Training set - validation set) data set에 적용한다. 그 중 validation set에서 성능이 가장 좋은 모델을 선택하고, 다시 전체 training set에 학습을 한다. 그런 다음에 해당 모델을 test set에 평가해서 generalization error를 측정한다.
하지만, validation set이 너무 작으면 부정확한 결과가 나올 수 있게 된다. 반면에 validation set이 너무 크면 남은 training set이 작아진다. 이게 좋지 않은 이유는, 최종 모델은 이후에 전체 training set에 학습될 것인데, 적은 training set에 학습된 모델은 성능이 좋기 어렵기 때문이다. 예를 들어, 마라톤에 뛸 사람을 뽑는데 단거리 스프린터를 뽑는 것과 같다.
그때 이 문제를 해결할 수 있는 방법은 여러 작은 validation set로 cross-validation (교차검증) 을 사용하는 것이다. cross validation이란, training set을 validation set으로 나눈 것은 같으나, 이 작업을 여러번 더 하는 것이다. 예를 들어, [1,2,3,4] 라는 training data set이 있을 때 처음에는 1을 validation set으로 설정하고 [2,3,4]는 training set으로 두는 것이다, 그 다음 회차에는 2를 validation set으로 설정하고 [1,3,4]를 training set으로 두는 것이다. 4번으로 전체 trainig set을 나눈다고 하면 총 4번 training 및 validation이 진행되는 것이다.
모델들의 evaluation들을 평균내서 더 나은 성능을 얻을 수 있게 된다. 하지만, 이 방법의 치명적인 문제는 학습시간이 validation set만큼 곱해진다는 것이다.
Subscribe via RSS
{kind=link}